英伟达获准对华出售H200芯片,需向美政府缴纳25%分成
2025-12-09
创新是制造企业赢得市场竞争的重要手段之一,也是获得高额利润的有效方式。过去,中国制造企业主要依赖产品的后期制造来获得利润,但是随着市场环境的变化,企业逐渐认识到——制造业的竞争实质是产品创新的竞争,拥有自主产品创新能力的企业,才能占领市场优势地位。在产品创新研发过程中,CAE是企业保证产品质量、减少成本、降低研发周期并快速响应市场的重要技术手段。因此,随着市场竞争节奏的不断加快,越来越多的制造企业开始引入CAE技术,并建立仿真分析部门。
另一方面,随着产品复杂程度的不断增大,企业仿真分析部门又面临着新的挑战。比如随着复杂产品模型所包含的数据量不断增加,为了实现对产品在实际工作中的性能表现更为精确的模拟,还需进行多学科仿真,这些仿真计算耗时越来越长,有时甚至需要几天,严重制约了产品研发进程。同时,在CAE软件环境中进行前后处理时,复杂模型的操作以及结果云图、动画的生成对图形显示的要求也越来越高,图形显示能力直接影响着工程师的操作体验以及分析结果获取的准确度。
幸运的是,近年来随着GPU加速计算的兴起,利用GPU来加速CAE分析已经成为一种趋势。GPU强大的并行计算能力能有效地对图形计算和仿真分析过程的大规模数据进行并行浮点处理,大幅加速产品的虚拟仿真分析过程,从而有效的缩短产品的研发周期。从成本上讲,CPU+GPU的搭配模式,不但能有效的减少企业购买的软件许可证费用,还可以降低企业在工作站购买上的硬件投入成本。
测试平台
为了更好的让企业了解GPU加速给CAE分析过程带来的性能提升,e-works特别安排了一次针对丽台Quadro K6000专业显卡的性能评测,而本次选用的平台为丽台最新推出的Maximus工作站。平台的详细配置如下:


丽台Quadro K6000是NVIDIA 2013年最新发布的顶级专业级工作站显卡,该显卡拥有2880个流处理器、240个纹理处理单元和48个ROP单元,单精度浮点性能为5.2TFlops,双精度浮点计算能力大约为1.7TFlops,也是目前超高端专业显卡市场计算性能最强大的显卡之一。同时,本次测试搭配的Maximus工作站也是丽台公司针对制造企业的高性能研发计算领域主推的平台,Maximus工作站可以同时搭配Tesla高性能图形计算卡和Quadro高性能专业显卡,实现设计和仿真应用的一体化,也是目前市场上唯一一款集产品的设计、仿真分析于一体的工作站平台,其最重要的价值是能实现设计与仿真计算的并行,从而大幅提升制造企业的产品研发效率。 图 1 丽台Quadro K6000专业显卡

图 2 丽台Maximus工作站WS2000

测试软件介绍 Abaqus是一套功能强大的工程模拟的有限元软件,其解决问题的范围从相对简单的线性分析到许多复杂的非线性问题。作为通用的模拟工具,除了能解决大量结构问题,Abaqus还可以模拟其他工程领域的许多问题,例如热传导、质量扩散、热电耦合分析、声学分析、岩土力学分析及压电介质分析。由于Abaqus优秀的分析能力和模拟复杂系统的可靠性使得它在各国的工业和研究中得到广泛的使用,在大量的高科技产品研究中也发挥着巨大的作用。 Abaqus软件从6.11版本开始可以支持NVIDIA的GPU加速技术,本次评测使用的是最新的Abaqus 6.13版本。
图 3 ABAQUS/CAE 6.13
性能测试
本次评测即在Abaqus环境下,测试丽台Quadro K6000通过GPU技术对CAE工作中图形显示增强和计算加速的效果。
1.评测思路
CAE分析主要有三个步骤,即:前处理、有限元求解计算、后处理。前处理中为产品建立合理的有限元分析模型,并进行单元属性定义、网格划分和载荷施加;有限元求解计算就是对有限元模型进行单元特性分析并求解的过程;后处理则根据工程或产品设计要求对有限元分析结果进行分析进而论证设计的合理性并优化,以满足客户对产品的设计需求。本次评测主要划分为以下几个步骤:
1)模型导入后的基本操作
如同其他CAE软件,Abaqus的建模功能有限,只适合建立简单部件。为了充分测试在CAE软件环境下的大模型显示效果及操作流畅度,本次评测选择从外部导入复杂模型,并对其进行平移,局部放大缩小,旋转,剖切,线框切换等基本操作。
2)有限元求解计算
作为整个CAE分析中计算强度最高的部分,有限元求解计算耗时直接影响整个CAE分析周期的长短。本次评测将记录在CPU数量调用相同时,无GPU加速、有GPU加速、GPU并行加速三种情况下求解计算过程所耗时间,进行对比分析得出GPU加速效果。
3)结果云图与动画的生成与显示
有限元计算完成之后,为了更加清晰直观的以图像形式显示出结果,需要生成应力应变云图及动画,复杂模型计算结果云图及动画的显示效果对显卡要求较高。
4)拼接屏
凭借 DisplayPort 1.2,Quadro K6000单卡可支持四台同时工作的显示器和最高 4k 分辨率。通过NVIDIA Mosaic 多显示器技术,在不牺牲性能或处理能力的情况下,可在一台工作站上轻松地将所有应用程序的画面扩展到多台高分辨率显示器或投影仪上。
2.CAE测试分析
本次选用的测试模型是一个发动机装配体,网格划分节点数:1060943,单元数665799,进行静力学分析。如图4所示。
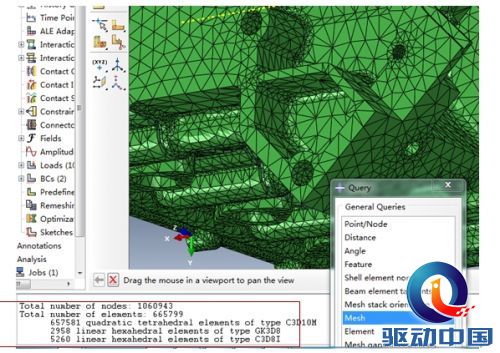
图 4 发动机装配体 模型基本操作
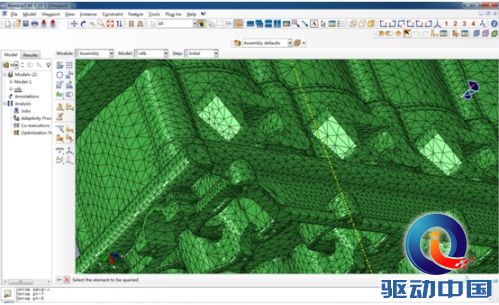
图 5 局部放大
图 6 平移操作
图 7 旋转操作
对模型载入、缩放、旋转以及编辑操作均比较流畅,基本上都在瞬间完成,这也说明在设计性能上完全能满足要求。同时,我们发现不论是模型的色彩还是线条都非常之清晰。以前也做过很多专业图形显卡及工作站的评测,但很少看到模型色彩有着如此良好的光泽度。对设计工程师而言,色彩真实且操作流畅的设计平台能大大的提升使用体验和效率。
4. 有限元分析
前处理完成后即开始进行有限元分析计算求解,这也是整个CAE分析过程中最耗费时间的环节,计算时间过长甚至严重拖慢整个产品开发流程。对此,借助近些年兴起的高性能计算技术,从硬件和软件两方面支持并行计算,可以大大缩短CAE计算求解时间。
以前的CAE应用评测中,都是对比调用不同核数情况下的求解耗时,得出多核调用对计算效率提高的水平。而近些年兴起的GPU技术除了提升显卡性能之外,也能通过其强大的运算能力,大大缩短计算时间,这种加速能力在对图形显示处理水平要求很高的CAE分析工作中则显得更为重要。因此本次评测一个很重要的目的就是测试GPU加速技术对CAE分析求解计算的加速水平如何。
本次测试平台搭配了2颗6核心12线程的处理器,因此共有12核心24线程可进行计算调用。另外,由于搭配了丽台Quadro K6000专业显卡,我们也通过将GPU的计算能力融入到分析中来感受计算性能的提升。表2为发动机装配体静载荷求解计算的耗时数据。
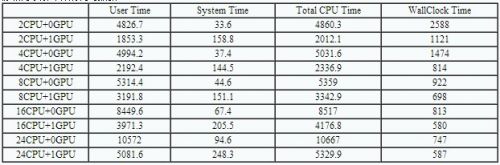
对于表2中的数据,我们可以主要关注前面三项,UseTime为模型的实际计算时间,System Time是指计算过程中的时间损耗(花费在传输以及指令流分配等过程的时间),Total CPU Time为整个CPU计算耗时,为User Time与System Time时间之和。对比表2数据,我们可以很清楚的发现在调用GPU和不调用GPU的场景中的计算时间有着非常大的区别。比如在2CPU场景中,调用GPU时,CPU总耗时长为2012.1秒,而不调用GPU时,CPU总耗时长为4860.3秒,GPU的加入将CPU的计算时长缩短了近60%。而这种时长的缩短在4CPU、8CPU、16CPU和24CPU场景中分别为:54%、38%、51%和51%,换言之,GPU计算能力的加入使得整机的图形计算性能提升了超过1倍。
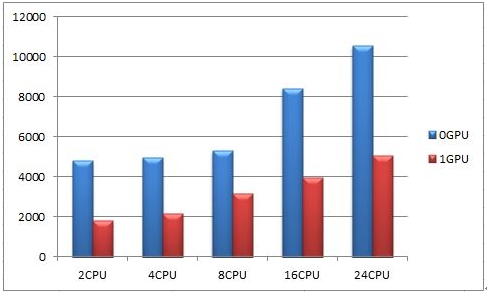
图 8 计算耗时对比(User Time)
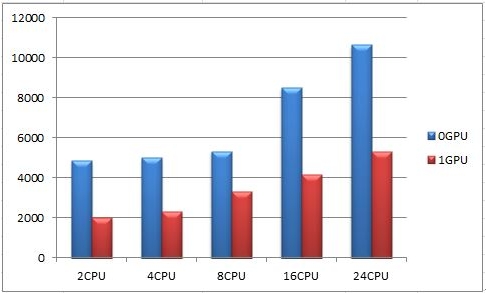
图 9 总计耗时对比(Total Time)
图8和图9为调用GPU和未调用GPU性能场景下的耗时对比。我们从数据中可以得出结论,即图形计算过程中并非调用了CPU核心越多,计算速度就越快。因为调用的CPU核心越多,计算资源的分配过程就越复杂,这会降低CPU的计算效率。比如在不调用GPU的情况下,2CPU和4CPU计算所花费的时间为4826秒和4994秒,而随着核心数量的增多,计算所耗费的时间也越长。因此,在进行大规模图形数据计算时,用户必须谨慎对待多核心的调用,在调用多核心进行计算时,尽可能的找到最佳的性能点。这种情况也同样出现在CPU与GPU之间,调用的CPU核心越多,耗费在CPU与GPU之间的资源分配时间越长,计算时间也就越长。
也有很多用户会经常问到,GPU为何能拥有如此强大的图形计算能力?这是因为GPU的出现一开始就是为了缓解CPU的计算压力,将CPU从图形计算中解脱出来。因此,GPU在架构设计上就非常适合于对大量图形数据的处理。GPU的内核设计的是并行架构,适合在短时间内处理大量类似结构的数据,比如图形计算、生物工程以及科研分析等。近年来,随着GPU技术的发展,GPU的性能越来越强大,因此出现了像Maximus工作站这样的集设计与分析于一体的图形工作站,通过搭配Quadro K6000专业图形显卡,大幅提升企业的研发设计效率。
结果云图与动画的生成与显示
有限元分析计算完成并得到了位移、应力或其它基本变量之后,就可以对计算结果进行评估。评估通常可以通过CAE软件可视化模块或其它后处理软件在图形环境下交互式进行。为了更为直观清晰呈现出计算结果,可视化模块可以读入计算结果文件并以多种方法显示结果,包括彩色等值线图、云图、动画等。 本环节直接在Abaqus图形界面环境中打开之前有限元分析步骤中生成的输出文件(后缀名.odb),然后利用Abaqus中的Visualization功能模块来生成结果云图和动画。

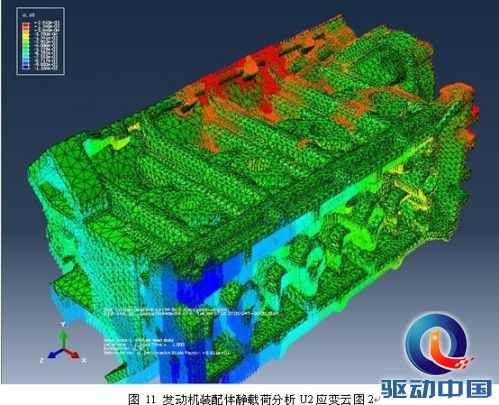
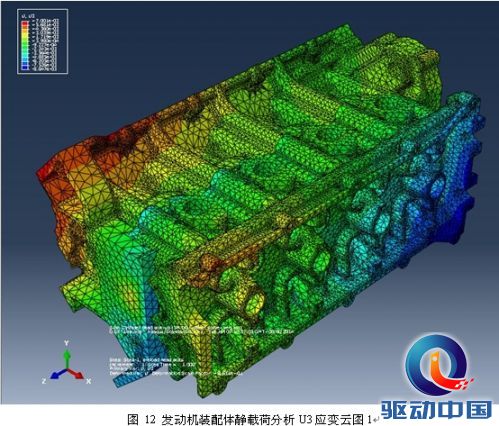
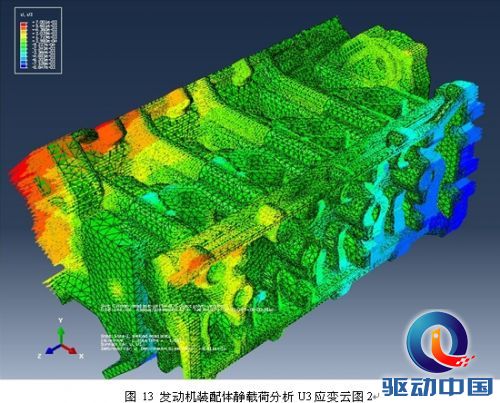
在评测中,图形展示清晰度高,能满足工程师对计算结果进行准确评估的要求,而且在对结果云图展示模式下的模型进行旋转平移、放大缩小等操作时,也不存在停滞感。随后对整个应变过程进行动画生成,动画画面清晰、播放过程中应变等值线变化流畅,能够很好的反映出整个过程。从动画中截取了四张图进行观察,等值轮廓线非常清晰,可以准确的反应出应变结果。
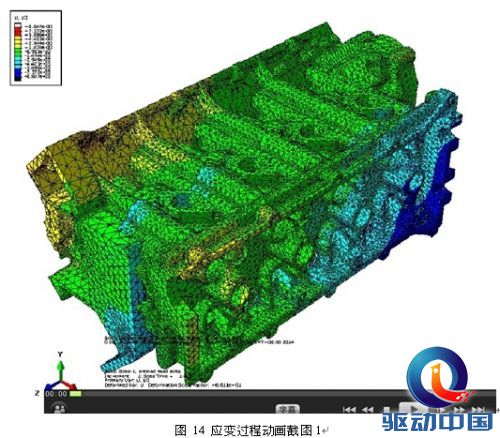
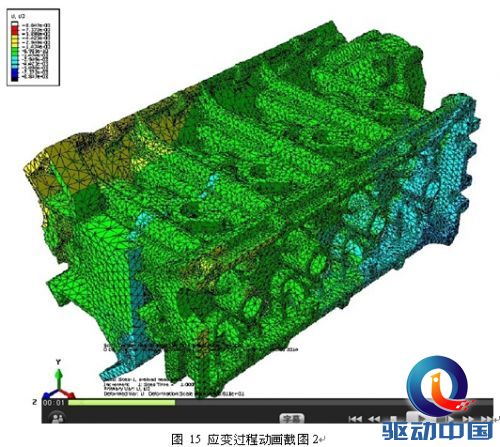
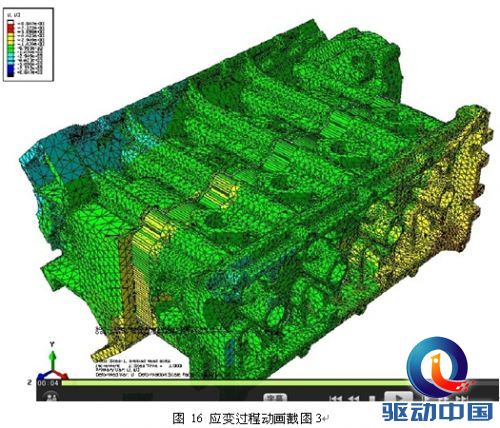
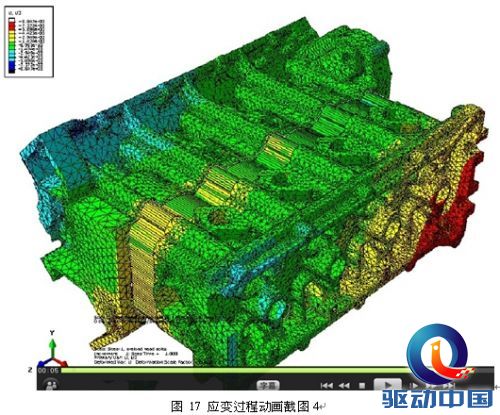
4.拼接屏
Quadro K6000单卡可支持四台同时工作的显示器,通过NVIDIA Mosaic 多显示器技术,在不牺牲性能或处理能力的情况下,可在一台工作站上轻松地将所有应用程序的画面扩展到多台高分辨率显示器或投影仪上。评测采用4台1080P高清显示器,2 x 2布局,实现单卡4屏拼接总分辨率3840 x 2160 @ 60Hz。
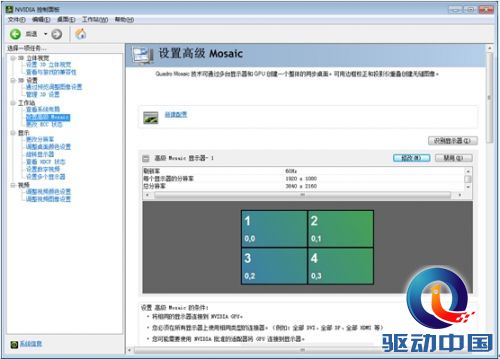
图 18 mosaic拼接屏设置

图 19 4台高画质显示屏拼接
总结
本次重点在于测试Quadro K6000工作站显卡在CAE平台上的性能,通过对发动机装配体进行有限元分析、云图生成以及拼接屏等操作来感受Quadro K6000工作站显卡给工程师设计与分析带来的性能提升。测试中我们首先对发动机模型进行了载入、旋转和修改操作,过程非常之流畅,感觉不到任何因性能不足而导致的拖影或卡屏的现象。在有限元分析过程中,我们通过对比在调用GPU和不调用GPU环境下的计算与分析耗时,测试过程充分证明了GPU能大幅加速模型的分析过程,测试结果显示,在调用GPU进行分析时,计算耗时能至少减少一半以上。对企业而言,产品设计与分析时间的缩短能减少产品的设计周期,从而提升企业的市场竞争力。最后我们还进行了云图生成及拼接屏的性能测试,云图生成主要是为了将有限元分析结果以图象或动画的形式来展现出来,使得测试的效果更加清晰。因此对图形显示性能要求较高。从测试结果看,云图生成过程非常顺利,而且在很短时间内就完成,生成的图像及动画质量也非常好,这充分显示了Quadro K6000工作站显卡的强大性能。同时,我们也深刻感受到了Maximus工作站稳定的性能。
在以往的测试中,e-works评测人员基本上选用的都是较为常用的图形工作站,但Maximus工作站与这些产品有所不同。在设计上,Maximus工作站有着更长的机箱,更强大的电源系统和风扇。在功能上,Maximus工作站能同时搭配Quadro工作站显卡和Tesla高性能计算卡,并能根据计算数据类型来自动选择Quadro或Tesla。这使得Maximus工作站不但能做基本的CAD图形设计,而且还能进行CAE仿真分析,满足企业大规模图形数据计算的需求。 总体来说,制造企业要提升市场竞争力,就必须设计市场需求的产品,更好、更快的根据市场需求开发用户需要的产品是考验企业市场生存能力的关键。因此,拥有一款好的开发和设计平台至关重要。
评论 {{userinfo.comments}}
{{child.content}}

 {{money}}元
{{money}}元




{{question.question}}
提交