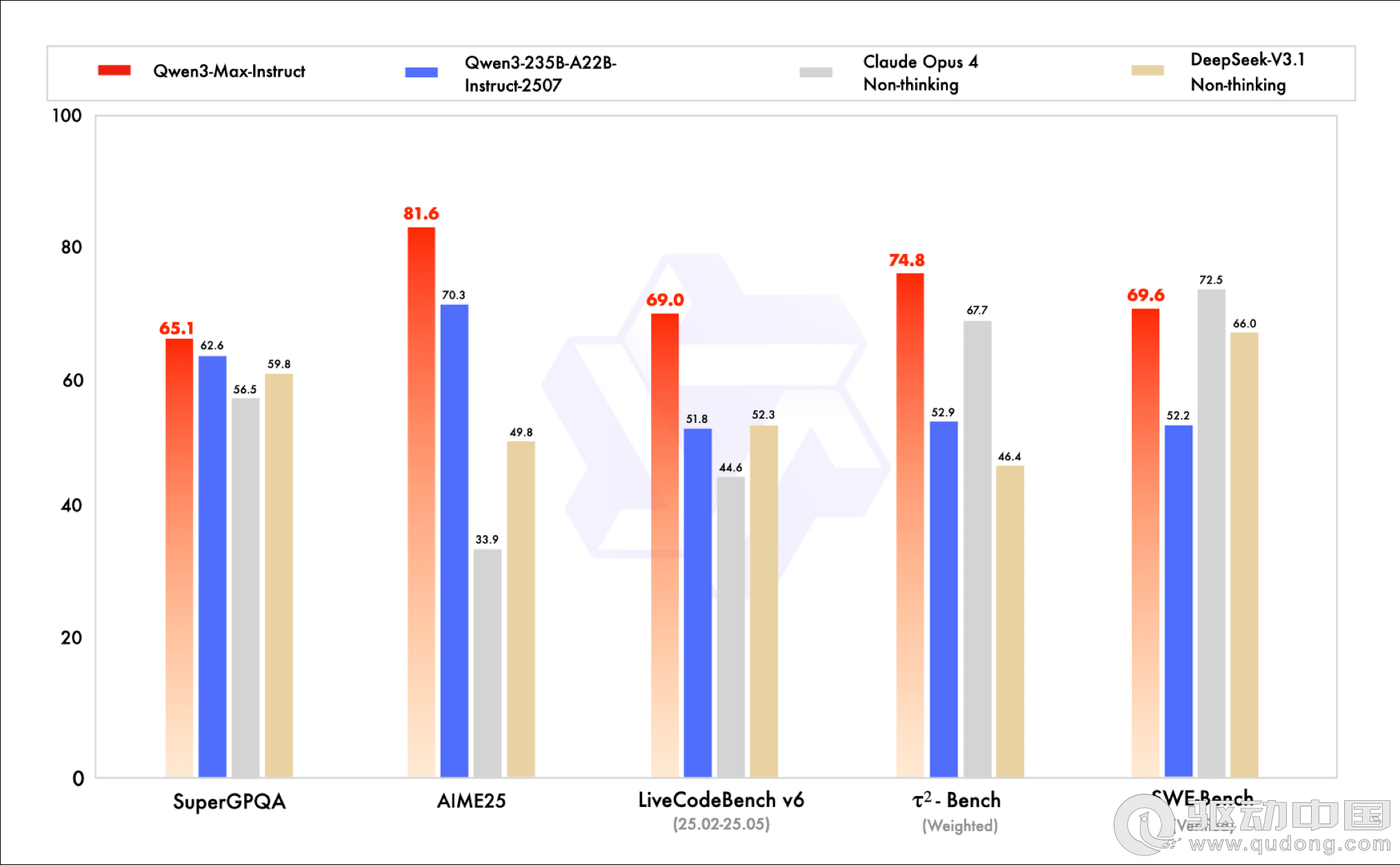
英伟达获准对华出售H200芯片,需向美政府缴纳25%分成
2025-12-09
同样属于架构革新的2012
过去的2012年里,无论是AMD还是NVIDIA都在图形架构技术层面上锐意进取,为我们带来了Compute Unit以及GPU Boost等等先进的技术,这些技术对于显卡产品的推动和促进作用是显著的。但对于我们以及整个业界来说,光有这些技术的进步还远远不够。
如果孤立存在,即便再优秀再精妙的技术,也无法转变成任何对我们有益的结果。只有将这些技术系统的融合在一起,调整好彼此的关系并令其发挥最佳的效果,技术的进步才能为我们带来切实的好处。所以对技术融合在一起所形成的架构进行回顾,也就变得有意义了。
技术的进步带动了AMD及NVIDIA在GPU架构层面的进步,让2012年不仅是技术进步年,更是GPU架构进步年。先后出现的GCN和开普勒(Kepler)体系都是双方技术进步的集大成者,它们成功地将双方全部的技术进步转化成了产品性能的提升,但细化到架构内部,双方的表现却并不都是积极向好的。同样的甚至是彼此一一对应的各种先进技术所组成的Tahiti和开普勒,最终却并没有一起收获成功。
胜利者从不缺乏赞美,赞美本身对胜利者以及旁观者都没有任何意义。只有找到导致问题的本源,并从由此探究更深层次的问题,我们才能明白图形界在过去的2012年里究竟经历了些什么。友站ZOL今天就带我们一览了2012年里出现在我们面前的所有图形架构,并揭示了决定AMD/NVIDIA架构之战结局的原因。

令人眼前一亮的Tahiti
AMD从2011年年中便曝光了全新一代的GCN(Graphic Core Next)架构体系,其后陆续到来的Tahiti、Pitcairn以及Cape Verde均基于该体系。GCN的整个信息披露过程相当系统和全面。按照AMD公布的信息,GCN将会带来大量革命性的技术革新,几乎将先前AMD GPU架构的各种问题一扫而空。在这些新技术情报带来的希望中,人们迎来了GCN的首款核心——Tahiti。

GCN的Tahiti架构打开了2012显卡架构年的大门
Tahiti是GCN体系的旗舰级核心,拥有超过43亿的晶体管规模。与上代的Cayman构架相比,其运算资源总量提升到了2048个流处理器,纹理拾取和载入与存储单元则提升至恐怖的512个,纹理过滤单元由Cayman的96个增加到了128个,但同时构成后端的ROP光栅单元与Cayman维持相同,均为32个。HD7970拥有全新设计的MC结构,6个64bit双通道显存控制器组合形成了全新的384bit显存控制单元,HD7970也因此采用了容量达3072MB的显存体系。

Tahiti构架特性
Tahiti架构的特色由五个主要的部分组成:
1、基于HKMG的台积电新28nm工艺。
2、包含了几何引擎、光栅化引擎以及一级线程管理机制的前端ACE( Asynchronous Compute Engine)。
3、负责处理运算任务及Pixel Shader的32个CU(Compute Unit)集群,包含在CU内部负责处理材质以及特种运算任务如卷积、快速傅里叶变换等的Texture Array,二级线程管理机制以及与它们对应的shared+unified cache等缓冲体系。
4、负责完成fillrate过程以及输出最终画面的ROP阵列,显存控制器MC(Memory Controller)以及PCI-Express3.0总线传输控制端。
5、负责视频回放及处理的UVD3.0单元,以及全新的负责视频编码部分的VCE。

HD7970构架
相对于前代的Cayman构架,Tahiti构架有了诸多触及灵魂深处的改动。它改进了Cayman的双前端并行体系,用更加灵活且效率更高的CU单元替代了强调吞吐但在效率层面显得“笨重”的VLIW Core,首次引入完善的Unified Cache并大幅改进了过往架构带有明显缺陷的缓冲体系,进一步强化了任务管理、仲裁机制以及架构的几何处理能力。
Tahiti所做出的一系列改进不仅明快而且目的性强烈,它扭转了AMD“以吞吐换延迟”的错误GPU架构方向,补完了先前架构的种种缺失并一扫AMD传统GPU架构笨拙且低效的痼疾,非常积极地迎合了DirectX 11对运算灵活度和效率的要求,将整个架构的运算和动作效率提升到了全新的高度,更为AMD通往通用计算等先进应用领域打下了基础。
宿命,开普勒登场
Tahiti的革新可以说是2012年架构革新的一剂强心剂,它不仅让我们看到了希望,更对竞争对手NVIDIA的新架构充满了期待。与Tahiti的开放和释放信心不同,NVIDIA接替Fermi的开普勒架构一直做足了保密工作,直到发布的一瞬间才让整个世界为之一顿。

性能功耗比革新巨大的开普勒
开普勒图形构架拥有超过35亿的晶体管规模,核心面积294平方毫米。与上代的Fermi构架相比,其运算资源总量提升到了1536个ALU,Texture Filter Unit由Fermi的64个增加到了128个,构成后端的ROP则下降为32个。GTX680同样拥有全新设计的MC结构,4个64bit双通道显存控制器组合形成了全新的256bit显存控制单元,GTX680也因此采用了容量达2048MB的显存体系。
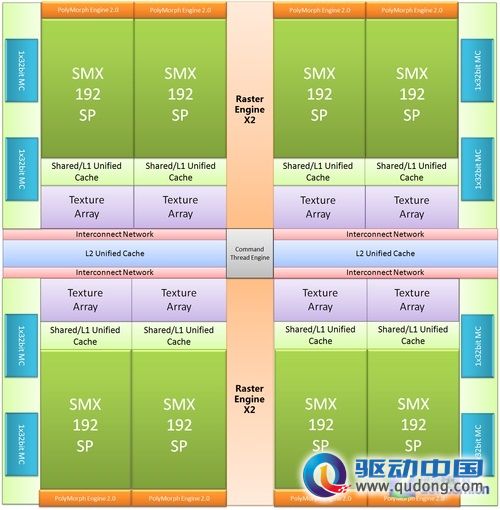
完整的GK104架构
GTX680的特色由六个主要的部分组成:
1、与Tahiti同样基于HKMG的TSMC全新28nm工艺。
2、与Fermi完全相同的4XGPC宏观并行设计。
3、8个包含了几何引擎、光栅化引擎以及线程仲裁管理机制的SMX单元。每个SMX单元包含一组改进型的负责出力几何任务需求的PolyMorph Engine,192个负责处理运算任务及Pixel Shader的ALU,16个负责处理材质以及特种运算任务如卷积、快速傅里叶变换等的Texture Array,二级线程管理机制以及与它们对应的shared+unified cache等缓冲体系。
4、负责完成fillrate过程以及输出最终画面的32个ROP单元阵列,以及对应L2 cache的4个64bit显存控制器MC(Memory Controller),负责视频回放及处理的PureVideo HD单元,以及全新的负责视频编码部分的NVENC。
5、根据功耗以及用户自定义负载需求实时调节GPU的GPU Boost功能,全新的TXAA以及抑制画面撕裂和顿挫的Adaptive VSync主动垂直同步技术。

开普勒架构GK104芯片核心照片
开普勒构架与Fermi构架在宏观层面上非常接近,其改进主要集中在微观结构层面,它使用了全新的SMX单元来替代传统ALU团簇结构,弃用了沿用数年的ALU分频机制,进一步改进了包括Cache/shared以及寄存器在内的缓冲体系,调整了线程仲裁机制并引入了全新的scheduling过程,为今后的架构发展做出了铺垫,引入了开创性的功耗性能管理机制,同时还强化了单卡多屏输出等功能性环节。
Tahiti与开普勒在宏观和微观结构对比中互有异同,Tahiti可以被看做是一个不同于AMD既往产品的,对称并行分布、core部分神似larrabee而uncore部分接近Fermi的全新结构,开普勒则可以被看做是一个4GPC并行,内部结构大幅调整优化的同时保留了之前产品优势的作品。Tahiti架构在维持吞吐的同时转向强调灵活性并进行了针对改进,而开普勒则在维持灵活性的前提下做出了平衡性能与功耗的努力。两者都在向着中线,也就是最佳的性能功耗比去靠拢。
评论 {{userinfo.comments}}
{{child.content}}

 {{money}}元
{{money}}元




{{question.question}}
提交